[Literate Programming] is a literary style that treats documents
as having dual qualities of literature and computer programs.
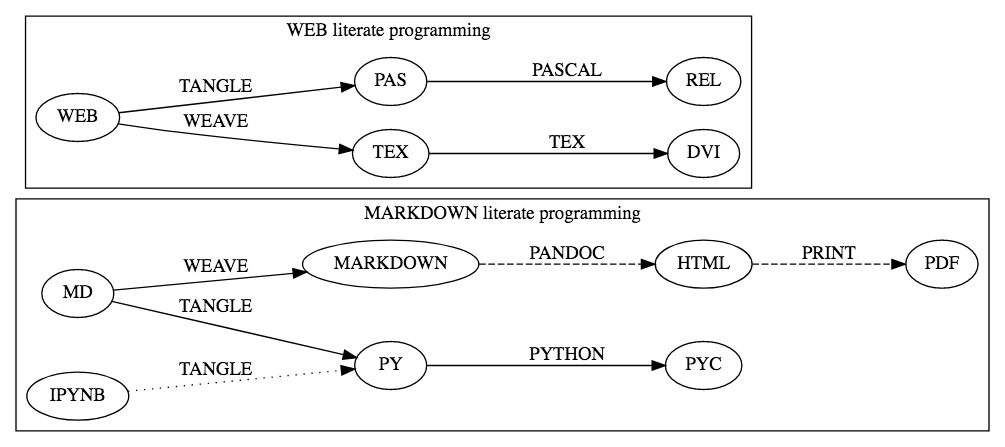
The original 1979 implementation defined the [WEB] metalanguage
of [Latex] and [Pascal]. pidgy is modern and interactive
take on [Literate Programming] that uses Markdown and Python
as the respective document and programming languages,
of course we'll add some other bits and bobs.
The result of the pidgy implementation is an interactive programming
experience where authors design and program simultaneously in Markdown.
An effective literate programming will use machine logic to supplement
human logic to explain a program program.
If the document is a valid module (ie. it can restart and run all),
the literate programs can be imported as Python modules
then used as terminal applications, web applications,
formal testing object, or APIs. All the while, the program
itself is a readable work of literature as html, pdf.
pidgy is written as a literate program using Markdown
and Python.
Throughout this document we'll discuss
the applications and methods behind the pidgy
and what it takes to implement a [Literate Programming]
interface in IPython.
- Literate Programming
- Computational Notebooks
- Markdown
- Python
- Jupyter
- IPython