Restoring and protecting Java code is an old and often-discussed issue. Due to the byte-code format used to store Java class files, which contains a lot of meta-information, it can be easily restored to its original code. In order to protect Java code, the industry has adopted many methods, such as obfuscation, bytecode encryption, JNI protection, and so on. However, regardless of the method used, there are still ways and means to crack it.
Binary compilation has always been considered as a relatively effective method of code protection. Java's binary compilation is supported as AOT (Ahead of Time) technology, which means pre-compilation.
However, due to the dynamic nature of the Java language, binary compilation needs to handle issues such as reflection, dynamic proxy, JNI loading, etc., which poses many difficulties. Therefore, for a long time, there has been a lack of a mature, reliable, and adaptable tool for AOT compilation in Java that can be widely applied in production environments. (There used to be a tool called Excelsior JET, but it seems to have been discontinued now.)
In May 2019, Oracle released GraalVM 19.0, a multi-language supporting virtual machine, which was its first production-ready version. GraalVM provides a NativeImage tool that can achieve AOT compilation of Java programs. After several years of development, NativeImage is now very mature, and SpringBoot 3.0 can use it to compile the entire SpringBoot project into an executable file. The compiled file has fast startup speed, low memory usage, and excellent performance.
So, for Java programs that have entered the era of binary compilation, is their code still as easily reversible as it was in the bytecode era? What are the characteristics of the binary files compiled by NativeImage, and is the intensity of binary compilation sufficient to protect important code?
To explore these issues, we recently developed a NativeImage analysis tool, which has achieved a certain degree of reverse effect.
First, we need to generate a NativeImage. NativeImage comes from GraalVM. To download GraalVM, go to https://www.graalvm.org/ and download version for Java 17. After downloading, set the environment variable. Since GraalVM contains a JDK, you can directly use it to execute the java command.
Add $GRAALVM_HOME/bin to the environment variable, and then execute the following command to install a the native-image tool
gu install native-imageWrite a simple Java program, for example:
java
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}Compile and run the above Java program:
javac Hello.java
java -cp . HelloYou will get the following output:
Hello World!
If you are a Windows user, you need to install Visual Studio first. If you are a Linux or macOS user, you need to install tools like gcc and clang beforehand.
For Windows users, you need to set up the environment variable for Visual Studio before executing the native-image command. You can set it up using the following command:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"If the installation path and version of Visual Studio are different, please adjust the related path information accordingly.
Now we use the native-image command to compile the above Java program into a binary file. The format of the native-image command is the same as that of the java command, with parameters such as -cp and -jar. If we use the java command to execute the program, we can use the same method for binary compilation, just replacing the java command with the native-image command. The command is as follows:
native-image -cp . HelloAfter a period of compilation, which may occupy a lot of CPU and memory, we can get a compiled binary file. The output file name is the lowercase of the main class name by default, which is hello here. If it is under Windows, it will be hello.exe. We can use the file command to check the type of this file, and we can see that it is indeed a binary file:
file hello
hello: Mach-O 64-bit executable x86_64Executing this file will produce the same output as using java -cp . Hello:
Hello World!
Using IDA to open the compiled hello generated in the previous steps, clicking on Exports will show the symbol table, where the svm_code_section symbol's address is the entry point for the Java main() function.
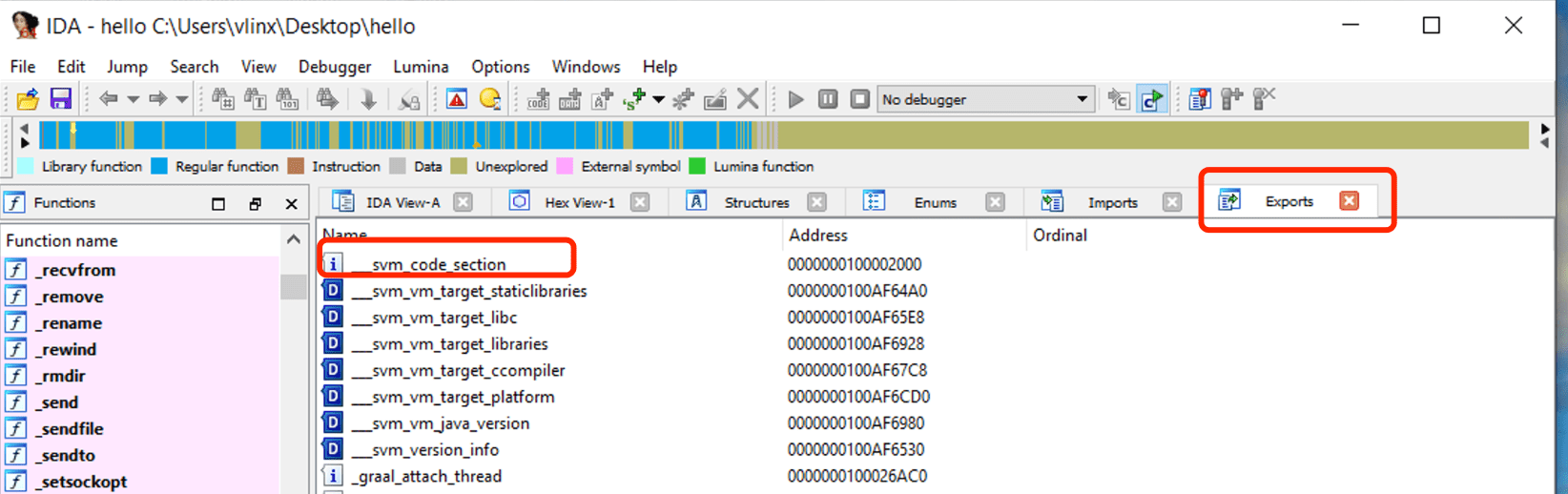
Navigating to this address and examining the assembly code, and using the F5 key to decompile it , we are not easy to discern the logic.
Double-clicking on sub_1000C0020 to see this functioin, results in an analysis failure prompt from IDA.
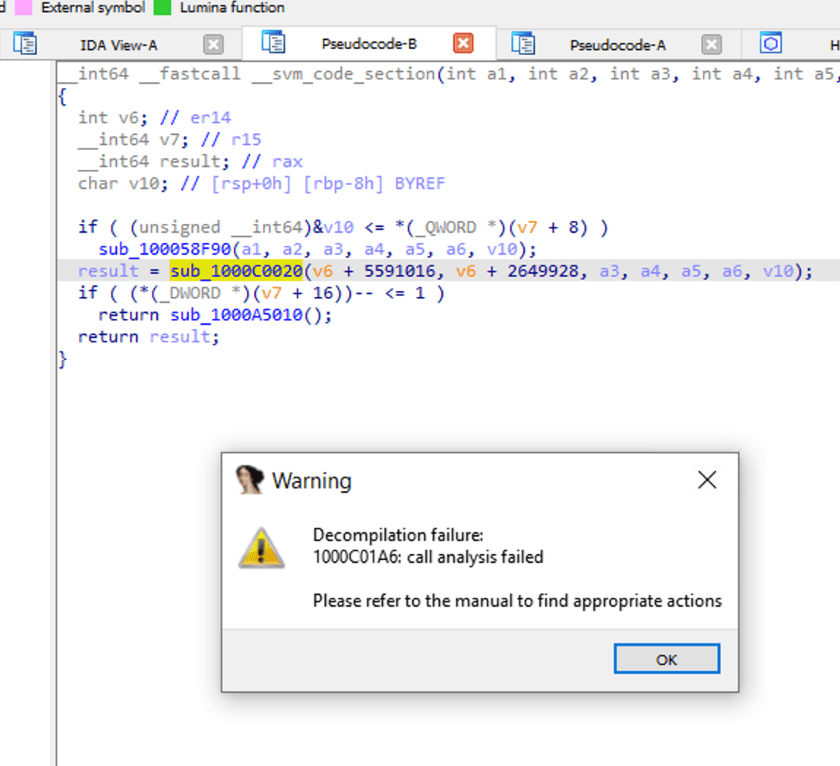
Since the compilation of NativeImage is based on JVM, it can be understood as adding a layer of VM protection to the binary code. Therefore, tools like IDA are unable to effectively reverse it in the absence of corresponding information and targeted processing measures.
However, regardless of the form, some basic elements of JVM execution, such as classes information, fields information, functions call, and parameters passing, must exist in bytecode or binary form. Based on this idea, the analysis tool developed by the author can achieve a certain degree of reverse effect, and with further improvement, it is capable of achieving a high level of restoration.
Visit https://github.com/vlinx-io/NativeImageAnalyzer/releases/tag/0.0.1 to download NativeImageAnalyzer.
Execute the following command for reverse analysis, currently only analyzing the Main function of the main class:
native-image-analyzer helloThe output is as follows:
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
returnLet's take a look at the original code:
public static void main(String[] args){
System.out.println("Hello World!");
}Now let's take a look at the definition of System.out in java/lang/System.java:
public static final PrintStream out = null;It can be seen that the out variable of the System class is a variable of the PrintStream type and is a static variable. When NativeImage is compiled, the instance of this class is directly compiled into an area called Heap, and the binary code directly obtains the instance of this class from the Heap area for calling. Now let's take a look at the code after restoration:
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
returnHere, java.io.PrintStream@0x554fe8 is the instance variable of java.io.PrintStream readed from the Heap area, and its memory address is 0x554fe8.
Now let's take a look at the definition of the java.io.PrintStream.writeln function:
private void writeln(String s) {
......
}Here, we can see that the writeln function has a parameter of type String. However, why are there three arguments passed in the restored code? Firstly, writeln is a class member method and only implicitly hides a this variable that points to the caller, that is just the first parameter passed, java.io.PrintStream@0x554fe8. As for the third parameter rcx, it is because in the process of analyzing the assembly code, it was judged that this function called three parameters. However, in fact, we know from the definition that this function actually only calls two parameters, which is an area that this tool needs to improve in the future.
Next, let's analyze a more complex program, such as calculating a Fibonacci sequence. The code is as follows:
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}Compile and execute:
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34After decompiling with NativeImageAnalyzer, we get the following code:
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
returnCompare the restored code with the original code:
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0corresponds to
int count = Integer.parseInt(args[0]);rdi is the register used to pass the first argument to the function, if it is In Windows, it is rdx. rdi = rdi[0] corresponds to args[0]. The code then calls java.lang.Integer.parseInt to parse and obtain an int value, which is then assigned to a variable sp_0x44 on the stack.
Next
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);corresponds to
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)What appears to be a simple string concatenation operation in the Java code is actually translated into three function calls: StringConcatHelper.mix, StringConcatHelper.prepend, and StringConcatHelper.newString. StringConcatHelper.mix calculates the length of the concatenated string, StringConcatHelper.prepend combines the byte arrays that hold the string contents, and StringConcatHelper.newString creates a new String object from the byte array.
We see two variable names of different types, sp_0x18 and tlab_0. Variables with names starting with sp_ are variables allocated on the stack, while variables with names starting with tlab_ are variables allocated on Thread Local Allocation Buffers. For more information on Thread Local Allocation Buffers, you can search for relevant information on the Internet.
We are assigning tlab_0 to Class{[B}_1, which means that this is an instance of the byte[] type object. [B is the Java descriptor for byte[] type, _1 indicates that this is the first variable of this type, and if subsequent variables of the same type are defined, the serial number will increase accordingly, such as Class{[B]}_2, Class{[B]}_3, etc. The same notation applies to other types, such as Class{java.lang.String}_1, Class{java.util.HashMap}_2, etc.
The logic of the above code briefly explains the creation of a byte[] array instance and assigns it to tlab0, the length of the array is ret_2 << ret_2 >>32. The reason why the length of the array is ret_2 << ret_2 >> 32 is that String calculates the length based on the encoding and requires a certain conversion of the array length. You can look up the relevant code in java.lang.String.java. Then, the ava.lang.StringConcatHelper.prepend function is used to concatenate 0, 1, and space into tlab0, and a new String object ret_30 is generated from tlab_0, which is passed to the java.io.PrintStream.write function for printing output. Actually, the parameters of the restored prepend function are not quite correct, and the positions of the parameters are also incorrect, which is an area that needs to be improved later.
After the two lines of Java code are converted into actual execution logic, it is still quite complicated. Later, we can simplify the pattern based on the currently restored code by analyzing and integrating it.
Let's continue
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();corresponds to
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
returnsp_0x44 is the input parameter that we passed to the program, the count. The for loop in the Java code is converted to a while loop. Essentially, they have the same semantics. The program executes the logic for count=3 outside the loop, and if count<=3, the program will exit without entering the loop. This is likely an optimization performed by GraalVM during compilation.
Let's take a look at the loop exit condition:
if(sp_0x44<=rcx)
{
break
}This corresponds to:
i < countAt the same time, rcx is also incremented during each iteration:
sp_0x34 = rcx
rcx = sp_0x34+1This corresponds to:
++iNext, let's see how the logic of adding numbers in the loop is reflected in the decompiled code. The original Java code is:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}The decompiled code is:
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}Other code in the loop body performs string concatenation and output operations as before. The decompiled code basically reflects the execution logic of the original code.
Currently, this tool is able to reconstruct program control flow and perform some degree of data flow analysis and function names reconstruction. In order to become a more useful tool, the following improvements are necessary:
- More accurate function name, parameter, and return value reconstruction
- More accurate object information and field reconstruction
- More accurate expression and object type inference
- Statement integration and simplification
The purpose of this project is to explore the feasibility of reverse engineering of NativeImage. Based on the current results, we can say that it is possible to reverse the NativeImage, which presents a greater challenge to code protection. Many developers believe that compiling software into binary code is sufficient for protection. For software written in C/C++, many tools, such as IDA, already have very good reconstruction results, and in some cases, the exposed information is even higher than that of Java programs. I have even seen some software distributed in binary form that does not remove symbol information such as function names.
Any code is made up of logic, and as long as it contains logic, it is possible to reverse it, the only difference lies in the difficulty of reconstruction, and code protection work is dedicated to maximize the difficulty of such reconstruction.